Kurz nach dem Brexit-Referendum 2016 verließ Dan seine Heimatstadt Sheffield und zog nach Freiburg. Nach mehreren Jahren des Studiums und der Arbeit an der Universität Freiburg kam er im April 2025 zu DataStrategies4Change. Hier blickt er auf sein erstes Jahr mit Daten in der echten Welt zurück:
Ich habe jahrelang in der Wissenschaft an neuronalen Netzen gearbeitet. Das wirkungsvollste, was ich seitdem gebaut habe? Ein Entscheidungsbaum.
Meine ersten Erfahrungen mit Machine Learning und KI habe ich in der Wissenschaft gesammelt – beim Entwerfen und Optimieren komplexer neuronaler Netze. Die Art von Arbeit, bei der Erfolg bedeutet, ein paar Prozentpunkte mehr auf Benchmark-Datensätzen herauszuholen1.
Ich habe schon immer gern technische Probleme gelöst – das hat mich von der Physik in die Neurowissenschaft und später in die Informatikforschung geführt. Dann bin ich vor rund einem Jahr als Data Scientist & Analyst zu DataStrategies4Change gekommen.
Ich hatte nicht erwartet, dass NGOs Deep Learning einsetzen – dafür fehlen Ressourcen und Expertise. Und selbst klassisches Machine Learning bringt reale Bedenken hinsichtlich Bias und Missbrauch mit sich. Dass viele Organisationen vorsichtig sind, ist also nachvollziehbar.
Aber ich bin davon ausgegangen, dass zumindest die Grundlagen vorhanden wären – klassisches Machine Learning, statistische Modellierung und so weiter. In der Realität sind die Ressourcen deutlich knapper als erwartet, und selbst diese Methoden liegen für die meisten NGOs außerhalb ihrer Möglichkeiten.
Aber die größere Überraschung war nicht, was fehlte. Sondern was stattdessen tatsächlich wichtig war.
Wirkung kam nicht von Modellen der neuesten Generation. Sie kam davon, Daten nutzbar zu machen, Ergebnisse verständlich aufzubereiten und Systeme zu bauen, denen Menschen tatsächlich vertrauen.
1: Ein Entscheidungsbaum kann revolutionär sein
Die Wissenschaft ist besessen vom neuesten Modell; NGOs haben diesen Luxus nicht. Ein jahrzehntealter Algorithmus wie der Entscheidungsbaum mag in der einen Welt unbeeindruckend sein – und in der anderen von unschätzbarem Wert.
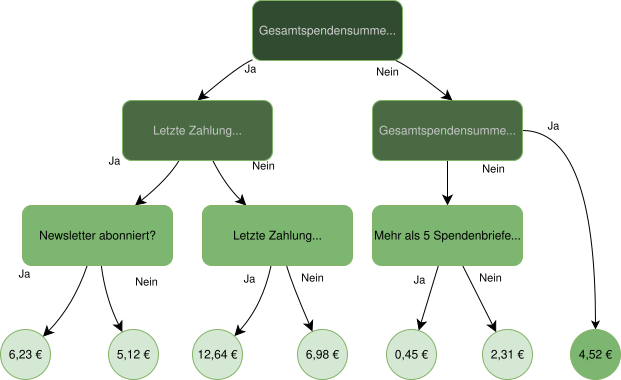
Wenn eine Organisation ihre Spender:innen mit statischen, vor Jahren von Hand geschriebenen Regeln analysiert, kann ein Entscheidungsbaum – ein Modell, das aus echten Daten eine Reihe von Ja/Nein-Fragen lernt – einen echten Unterschied machen. Nicht weil er komplex ist, sondern weil er datengetrieben ist: Er betrachtet alle Daten, lernt aus echten Ergebnissen und aktualisiert sich nach jeder Kampagne.
In einem Projekt, an dem wir gearbeitet haben, verschickten unsere Modelle fast 20 % weniger Briefe – bei gleichzeitiger Steigerung des Nettoüberschusses um 6,3 % (mehr dazu hier). – In meinem Jahr bei DS4C konnte ich dieses Modell noch weiter verbessern und so der NGO helfen, sie schon seit ein paar Jahren alle Mailing-Selektionen mit unseren Algorithmen macht.
Es ist das Pareto-Prinzip2 in Aktion: ein relativ einfaches Modell, das den Großteil der Wirkung erzielt. Darüber hinauszugehen – auf marginale Verbesserungen hin – kann unverhältnismäßig viel Aufwand erfordern.
Und das war mein größter Perspektivwechsel: Den größten Unterschied macht man nicht mit einem unglaublich komplexen Modell, sondern mit etwas, das besser ist als das, was vorher da war – und das innerhalb der vorhandenen Systeme und Ressourcen funktioniert.
2: Daten sind wertvoller, als man denkt
Eine Organisation, mit der wir zusammengearbeitet haben, hatte E-Mail-Adressen für jeden Kontakt – sah diese aber nicht als nützliche Daten an.
Ein bisschen String Parsing später hatten wir brauchbare Muster: etwa ob eine E-Mail-Adresse von einer Universität oder einem Unternehmen stammte. Nichts Ausgefallenes. Aber es hat das Modell verbessert.
Das kommt ständig vor. NGOs tracken Engagement oft nicht systematisch, speichern nützliche Daten inkonsistent oder messen nur die halbe Wirkung – zum Beispiel Spenden oder Spender:innen, aber nicht beides zusammen. Manchmal wissen sie nicht einmal, wie viel ihnen an Dauerspenden für das kommende Jahr zugesagt wurde.
Das ist kein Kompetenzproblem. Es ist ein Datenkulturproblem. In den vorhandenen Systemen steckt meistens weit mehr Signal, als irgendjemand ahnt.
3: Vertraue nichts in der Datenbank
Daten in der echten Welt können… auf sehr menschliche Weise chaotisch sein. Nicht weil die Leute nachlässig sind – sondern weil Systeme sich mit der Zeit weiterentwickeln, Teams wechseln und Dokumentation selten mithält.
Das führt zu:
- stillen Fehlern
- Data Leakage
- Definitionen, die sich im Laufe der Zeit ohne Dokumentation geändert haben
- Daten, die niemand erklären kann
Der einzige Weg da durch führt über Gespräche mit den Menschen hinter den Daten – denjenigen, die wirklich wissen, was die Daten bedeuten.
4: Sie wollen in die Box schauen

Ich hatte erwartet, dass Explainability wichtig ist. Nur nicht so.
Ich dachte, es würde um Modellverfeinerung gehen.
Und das tut es – bis zu einem gewissen Punkt. Aber darüber hinaus geht es um Vertrauen. Denn ein Modell zu verfeinern ist sinnlos, wenn die Leute ihm nicht vertrauen – oder dir nicht zutrauen, verantwortungsvoll mit ihren Daten umzugehen.
In der Praxis ist es einfacher als erwartet. Organisationen wollen Vorhersagen nachvollziehen, Ergebnisse auf Plausibilität prüfen und Resultate mit ihrem Fachwissen abgleichen. Was Vertrauen aufbaut, sind nicht Genauigkeitswerte – sondern Transparenz.
Deshalb setzen wir fast immer auf Glassbox-Modelle: Modelle, deren Logik man vollständig einsehen und nachvollziehen kann.
Und dieses Vertrauen endet nicht beim Modell. Viele Organisationen sind – zu Recht – vorsichtig bei KI-Systemen, besonders angesichts der häufigen Assoziationen mit Bias, Intransparenz und Missbrauch. Gleichzeitig verlassen sie sich aber oft stark auf externe Plattformen und Cloud-Anbieter:innen und speichern sensible Daten teilweise außerhalb ihrer eigenen Jurisdiktion.
Die Vorsicht ist also da. Sie wird nur nicht immer konsistent angewendet. Das ist keine Kritik – es spiegelt wider, wie schwierig es ist, einzuschätzen, wo die echten Risiken liegen. Es ist auch der Grund, warum wir bewusst darauf achten, wie wir mit Daten umgehen: Berechnungen laufen auf unserer eigenen Infrastruktur unter unserer Kontrolle in unserem Büro und nicht auf externen Cloud-Diensten.
Aber es zeigt eine größere Chance: Systeme zu bauen, die nicht nur wirksam, sondern auch verständlich sind – und fundiertere Gespräche darüber zu führen, wo die echten Risiken und Vorteile tatsächlich liegen.
5: Die Intuition der Menschen über KI stimmt nicht ganz
Was Menschen für einfach und was sie für schwer halten, ist bei KI oft genau vertauscht.
Artikel zu finden, in denen ein:e Politiker:in eine Idee bewirbt, ohne sie beim Namen zu nennen – das klingt schwierig. Ist es aber nicht: Der richtige RSS-Feed, Semantic Search und ein guter Prompt, und es funktioniert.
Andererseits: „Vergleich einfach dieses Rechtsdokument mit anderen” klingt simpel – bis man merkt, dass es auf Dutzende externer Gesetze verweist, die nicht enthalten sind.
Warum das wichtig ist
Ich habe diesen Job angenommen, weil ich gerne mit Daten arbeite und Probleme löse – und es besonders erfüllend ist, diese Fähigkeiten für Anliegen einzusetzen, an die ich wirklich glaube.
Diese Organisationen leisten wichtige Arbeit mit begrenzten Mitteln. Schon kleine Verbesserungen in der Datennutzung können Zeit, Geld und Aufmerksamkeit für das freisetzen, was wirklich zählt.
Der NGO-Sektor braucht keine hochmoderne KI.
Er braucht Menschen, die bereit sind, ihn dort abzuholen, wo er steht – und ihm beim nächsten Schritt zu helfen.